
Knowledge Graph 101: What Is It, How It Works & Why It Matters?
“There are only two hard things in Computer Science: cache invalidation and naming things.”
Well, it turns out that with knowledge graphs, we face the inverse problem. Google came up with that great name in 2012, and it caught everyone’s attention. Since then, dozens of attempts at defining it have appeared from all directions. These definitions often diverge and sometimes even contradict each other. Some are useful, some are biased toward certain technology stacks or products, and some just leave you with more questions than certainties.
In this blog post, I’ll give you a no-nonsense definition of knowledge graphs, how they work, what they might mean to different people, and why you should care.

Let’s start with the basic: Knowledge graphs are a means, not an end in themselves.
When Google introduced the term “knowledge graph,” they did not formally define it. Instead, they described how it transformed the search experience by moving from “strings to things”; in other words, from just finding web pages containing the search keywords to understanding the meaning of the search string and returning contextualized answers.
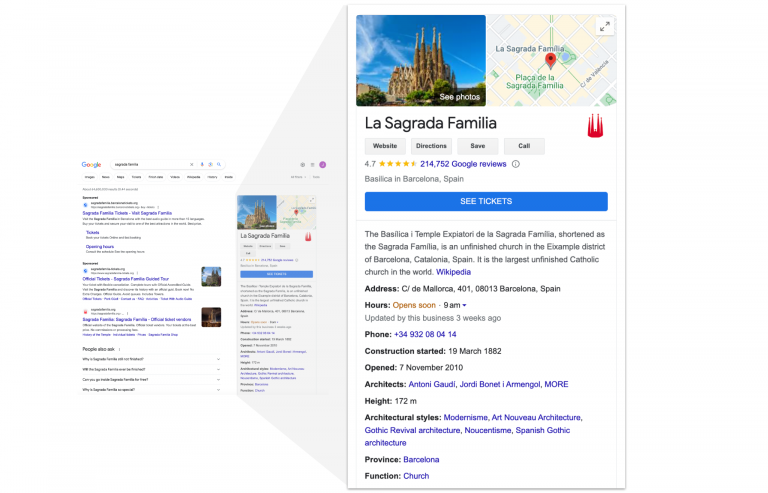
The idea is simple; when you search for “Sagrada Familia,” not only do you get a list of pages mentioning it but also a summary box containing facts about it (they called it a “knowledge panel”): Sagrada Familia is a church in Barcelona, a city in Spain; and its author was the architect Antoni Gaudi who lived between 1852 and 1926.
This not only enriches the results returned by the search but also drives highly valuable automated integrations: locations can be explored on a map or visited IRL by booking a flight, products can be purchased in online stores, etc.
Graph: The Foundation of Knowledge Graphs
This world of possibilities was enabled by just organizing information as a graph. A graph is formed of nodes and relationships. Any person, object, location, or event can be a node. The relationships describe any kind of interaction between nodes; for example, an event takes place at a location, a person knows another person, etc. Nodes and relationships will be annotated with their types and described by a collection of attributes that characterize them. For instance, a node representing a city will typically have a property indicating its current population or its geographical location, a person would have a date of birth, a name, and so on.
Once data is represented in a connected fashion, exploring it is easy, and the context around a topic of interest is just the neighborhood around it in the graph.
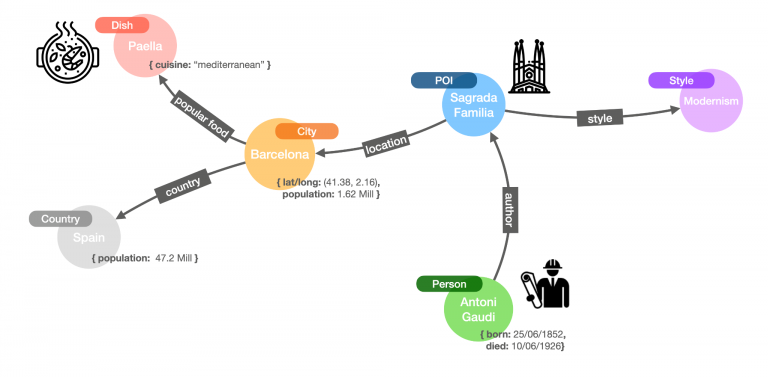
The same principle applies to so many other scenarios. Let’s suppose you work in client services, and the churn prediction system has flagged a particular user. Your job is to retain customers, so you will first try to understand what’s going on. What’s the recent usage pattern? Is there any negative interaction with customer support that could reveal some dissatisfaction? What type of services do they subscribe to?
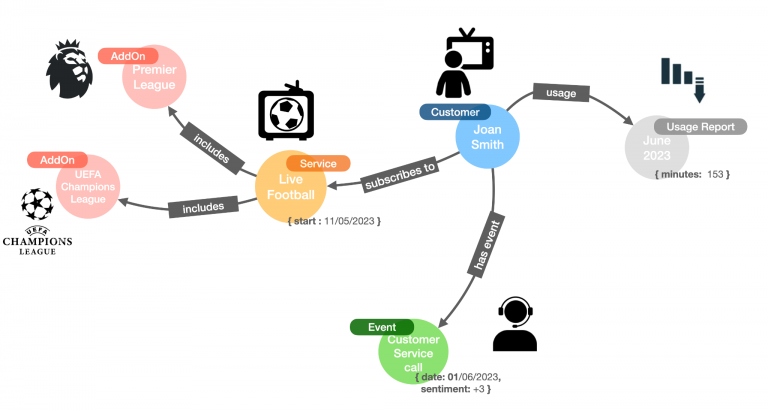
A contextualized view like this one would be invaluable to understanding how to offer them a better experience and, in the short term, for you to determine: how to act to prevent them from leaving, which promotion to push, what discount to offer, etc.
You want to know “all about the customer,” yet this seemingly easy question translates into something that is not very easy to express without writing many lines of code – unless you have a knowledge graph.
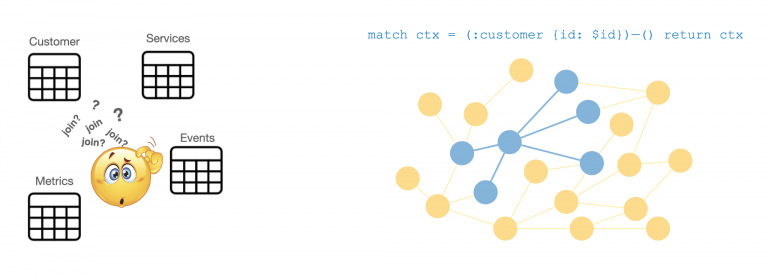
What Exactly Is a Knowledge Graph?
A knowledge graph captures information about foundational (key/main) entities in a domain or a business and the relationships between them.
This is the most general definition I could think of, and because of its generality, it will probably leave you unsatisfied, so here are some more refined ones depending on who you are:
If you’re a developer, you will normally build applications that consume the information in the knowledge graph. For you, a knowledge graph is a database with which you’ll interact through some form of API offering you structural primitives, like “For a given item A, retrieve all other items related to it,” “Is there a direct or indirect connection between items A and B? If so, how many different ones exist?” or “What is the most significant path connecting items A and B?” Richer knowledge graphs will offer pattern-based query languages like Cypher, GQL, or SPARQL, but simpler ones may offer more basic interfaces, for example, a method returning all related items for a given one.
If you’re a data scientist, you will see a knowledge graph as an augmented feature store for enriched (connected) data, where you will be able to compute and access (and operationalize and govern) structural features for ML. Think of centrality metrics for a given data point, the different data clusters it belongs to, or the distance to a given point in the graph. All these features completely escape table-based datasets and significantly improve the accuracy of your predictive models.
If you’re a data engineer, a knowledge graph is a data store where you’ll integrate data from different sources. You can think of it as a connected data warehouse, lake, or ODS, depending on its function. You will normally care more about the internals of the knowledge graph, how it’s built, how it’s updated, and how its quality is controlled or its content governed so that consumers, like data scientists and developers, can use it reliably and efficiently.
If you’re a non-technical person, maybe a business analyst, a fraud specialist, an investigative journalist, or the customer support I described earlier, a knowledge graph is a database that you will interact with through some visual or navigational interface. You will “click around and follow relationships” to understand things in context. But sometimes you will not see the knowledge graph at all – think, for example, a conversational interface or Google’s semantic search example that I described in the opening. You won’t see the graph, but you’ll still benefit from it in the quality, accuracy, and explainability of the answers you get from it.
Why Knowledge Graphs: Smarter Data
Knowledge graphs are connected to a long history of research in an area of artificial intelligence called knowledge representation. The idea behind it is to combine data and business logic together in a common representation that enables the automation of complex tasks.
You might be wondering: What does that mean exactly? How do we capture business logic in a graph? Why would I want to do that?
Business logic normally lives in the applications that make use of the data, doesn’t it? Correct, but that’s not necessarily a good thing for a number of reasons: the logic needs to be replicated across applications with significant duplication of effort and with a risk of inconsistency.
For example, think of two applications or two reports that implement different definitions of what a customer is. Maybe one includes churned customers, and the other one does not. Or maybe one of them considers churned customers as those with a canceled subscription, but the other just count any customer with a given period of inactivity? Even if they’re working on the same data, they could produce different results. It would be obviously beneficial to centralize and standardize the definition of critical business entities and metrics.
If we could bring those definitions closer to the data, we would be making our data “smarter” and improving consistency and coherence in its use across applications. We want to move as much as possible of the implicit intelligence hidden in applications and bring it closer to the data so it can be reused by multiple data products maximizing data usage and minimizing inconsistency.
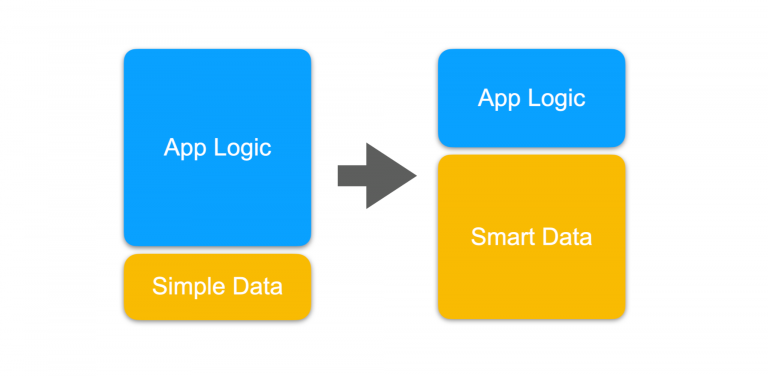
We sometimes refer to this as making explicit the semantics of data and is a distinctive feature of knowledge graphs.
How Do Knowledge Graphs Work: Semantics & Ontologies
The types of entities and relationships in a knowledge graph are not limited, and new ones will be added over their lifetime. Your initial knowledge graph may contain information about locations and restaurants, but then you decide to extend it with details on the types of cuisine and ingredients served at the restaurants or maybe with other types of local businesses like hair salons, bookstores, or dry cleaners.
In order to make your knowledge graph understandable in a consistent way, a common practice is to enrich it with a semantic layer describing the types of entities and relationships that it contains. These descriptions are often referred to as ontologies. They can be seen as a business-oriented descriptive schema for the information in the knowledge graph, but the most interesting thing is that they are also described as a graph and can coexist with your data. It may sound a bit confusing, but you’ll see later on that it can be very powerful.
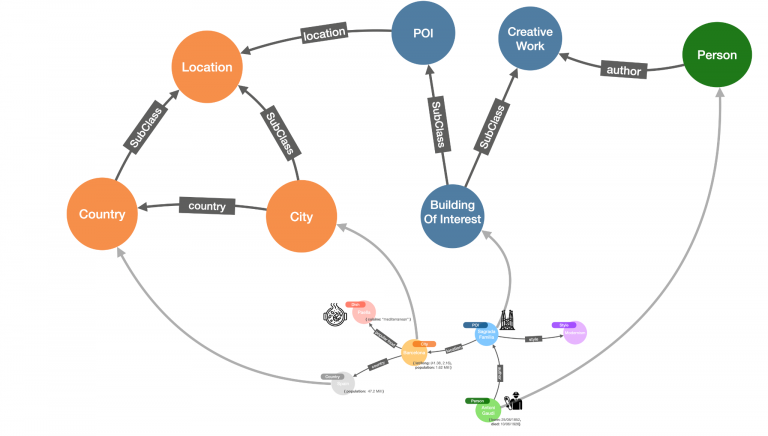
As you can see in the figure, an ontology provides a map and a compass over the data in the graph. A surface to search for data before you start searching in the data. The ontology in the previous figure tells us that the graph contains information about points of interest, which is associated with locations. We also see that buildings of interest are a specific type of POI that also happen to be creative works and, as such, can be associated with their authors. This information provides additional guidance and is extremely useful for understanding what’s in the knowledge graph.
But ontologies are not only descriptive, they are also actionable. Because they are stored as nodes and relationships in the graph, you can write logic (queries/patterns) that traverse from the data plane to the ontology and back, providing richer answers like: “Because you’re interested in Sagrada Familia, a building of interest located in the city of Barcelona, you may also be interested in the Rioja wine region as it happens to be a different type of point of interest in another city in the same country.”
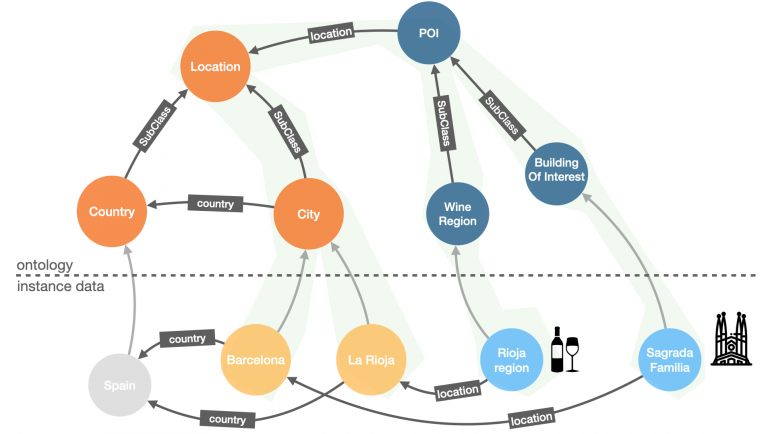
The generation of this type of rich answer is called inference, and you can see it in action in the previous image. The inference is basically reaching conclusions by applying evidence and reasoning.
The evidence is the facts in your graph (the lower plane): “Sagrada Familia is a building of interest in the Spanish city of Barcelona” and “Rioja is a wine region in Spain.” And the reasoning comes from the ontology (the upper plane): “Wine regions and historic buildings are types of points of interest” and “Points of interest are associated with locations.” You can see how the combination of the two provides the answer, and the interesting thing is that it can be fully automated based on graph traversals.
For you, impatient data practitioner, here is an example of how this kind of inference logic could be expressed in Cypher (the most widely adopted graph query language invented by Neo4j):

The syntax is not important for now. The important bit is that when your data and knowledge are managed in the form of a graph, pretty sophisticated logic can be expressed in a concise way. And equally important, evaluated efficiently at scale over large volumes of data. But we will talk about this in more detail in future posts. For now, just keep this intuition of inference as navigating up and down the data and semantic layers in a knowledge graph.
Also, know that you can keep adding knowledge into this semantic layer by including richer descriptions like taxonomies (hierarchical classifications) that provide additional meaning and offer additional ways to exploit the data in the knowledge graph.
A small example of this is the hierarchical classification of points of interest in the previous example, but you can think of it also in larger examples like rich product catalogs where products are classified by function, shape, style, and materials, offering even richer ways to run inferences or define semantic similarities.
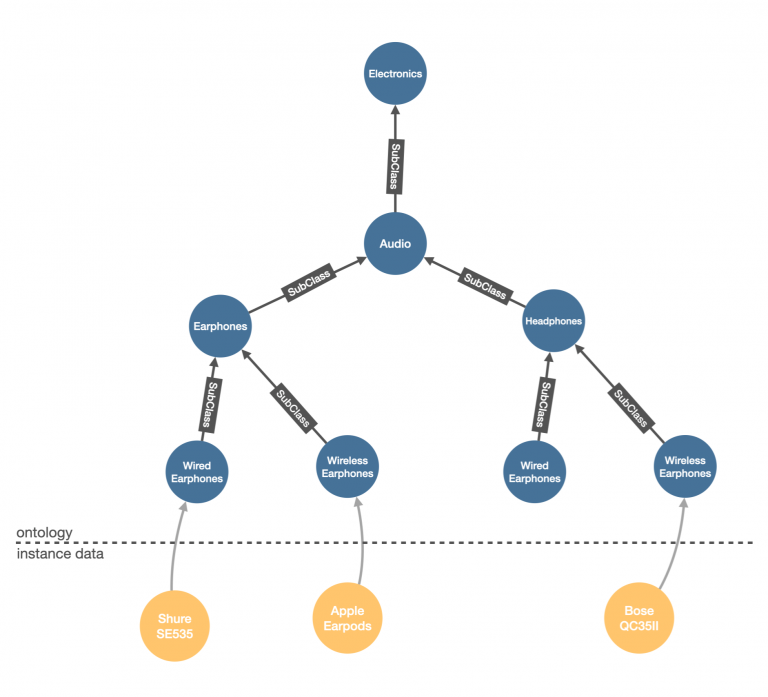
If you state in your ontology that wireless earphones are a subcategory of earphones and earphones are a subcategory of audio equipment, this classification typically forms a tree or, more generally, a DAG. When the classification is overlaid on top of your data, you are enabling rich semantic search, “You’re searching for earphones, so products labeled as wireless earphones are a valid answer to your question,” or complex inferences to generate explainable recommendations or alternatives, “Apple AirPods are out of stock, but you may be interested in the Shure SE535, which are a wired alternative.”
Reactie toevoegen